Iklan
Apakah Anda percaya pada gagasan bahwa begitu sesuatu diterbitkan di Internet, itu diterbitkan selamanya? Nah, hari ini kita akan menghilangkan mitos itu.
Yang benar adalah bahwa dalam banyak kasus sangat mungkin untuk menghapus informasi dari Internet. Tentu, ada catatan halaman web yang telah dihapus jika Anda mencari Mesin Wayback, Baik? Yup, tentu saja. Di Mesin Wayback ada catatan halaman web kembali bertahun-tahun - halaman yang Anda tidak akan menemukan dengan pencarian Google karena halaman web tidak ada lagi. Seseorang menghapusnya, atau situs web dimatikan.
Jadi, tidak ada jalan keluarnya, kan? Informasi akan selamanya terukir menjadi batu Internet, ada untuk generasi untuk melihat? Ya tidak.
Yang benar adalah bahwa sementara itu mungkin sulit atau tidak mungkin untuk menghapus berita utama yang telah berkembang biak dari satu situs web berita atau blog ke yang lain seperti virus, sebenarnya cukup mudah untuk sepenuhnya menghapus halaman web atau beberapa halaman web dari semua catatan keberadaan - untuk menghapus halaman itu untuk kedua mesin pencari dan juga itu
Mesin Wayback Mesin Wayback Baru Memungkinkan Anda Melakukan Perjalanan Visual Kembali Dalam Waktu InternetTampaknya sejak Wayback Machine diluncurkan pada tahun 2001, pemilik situs telah memutuskan untuk membuang back-end yang berbasis Alexa dan mendesain ulang dengan kode sumber terbuka mereka sendiri. Setelah melakukan tes dengan ... Baca lebih banyak . Ada tangkapan tentu saja, tetapi kita akan sampai ke sana.3 Cara untuk Menghapus Halaman Blog Dari Internet
Metode pertama adalah yang digunakan oleh sebagian besar pemilik situs web, karena mereka tidak tahu yang lebih baik - cukup menghapus halaman web. Ini mungkin terjadi karena Anda menyadari bahwa Anda memiliki duplikat konten di situs Anda, atau karena Anda memiliki halaman yang tidak ingin Anda tunjukkan di hasil pencarian.
Cukup Hapus Halaman
Masalah dengan sepenuhnya menghapus halaman dari situs web Anda adalah karena Anda telah membuat halaman di net, kemungkinan ada tautan dari situs Anda sendiri serta tautan eksternal dari situs lain ke situs tersebut halaman. Saat Anda menghapusnya, Google segera mengenali halaman itu sebagai halaman yang hilang.
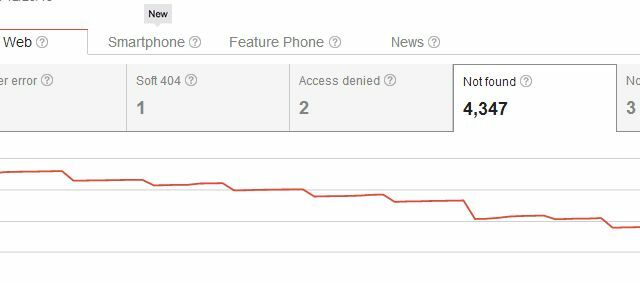
Jadi, dalam menghapus halaman Anda, Anda tidak hanya menciptakan masalah dengan kesalahan perayapan "Tidak ditemukan" untuk diri Anda sendiri, tetapi Anda juga membuat masalah bagi siapa saja yang pernah menautkan ke halaman. Biasanya, pengguna yang masuk ke situs Anda dari salah satu tautan eksternal itu akan melihat laman 404 Anda, yang bukan a masalah besar, jika Anda menggunakan sesuatu seperti kode 404 khusus Google untuk memberikan saran atau bantuan yang bermanfaat bagi pengguna alternatif. Tapi, Anda pikir mungkin ada cara yang lebih anggun untuk menghapus halaman dari hasil pencarian tanpa memulai semua 404 itu untuk tautan masuk yang ada, kan?
Ya ada.
Hapus Halaman Dari Hasil Pencarian Google
Pertama-tama, Anda harus memahami bahwa jika halaman web yang ingin Anda hapus dari hasil pencarian Google bukan halaman dari situs Anda sendiri, maka Anda kurang beruntung kecuali ada alasan hukum atau jika situs telah memposting informasi pribadi Anda secara online tanpa Anda izin. Jika itu masalahnya, maka gunakan Google pemecah masalah penghapusan untuk mengirim permintaan agar halaman dihapus dari hasil pencarian. Jika Anda memiliki kasus yang valid, Anda mungkin menemukan beberapa kesuksesan dengan menghapus halaman - tentu saja Anda mungkin memiliki kesuksesan yang lebih besar menghubungi pemilik situs web Cara Menghapus Informasi Pribadi Palsu di InternetPrivasi online tidak dijamin lagi. Pelajari cara melaporkan situs web dan menghapus informasi pribadi dari internet. Baca lebih banyak seperti yang saya jelaskan bagaimana melakukan kembali pada tahun 2009.
Sekarang, jika halaman yang ingin Anda hapus dari hasil pencarian ada di situs Anda sendiri, Anda beruntung. Yang perlu Anda lakukan adalah membuat a robots.txt arsipkan dan pastikan bahwa Anda tidak mengizinkan halaman tertentu yang tidak Anda inginkan dalam hasil pencarian, atau seluruh direktori dengan konten yang tidak ingin Anda indeks. Di sini terlihat seperti apa pemblokiran satu halaman.
Agen pengguna: * Disallow: /my-deleted-article-that-i-want-removed.html
Anda dapat memblokir bot dari merayapi seluruh direktori situs Anda sebagai berikut.
Agen pengguna: * Disallow: / content-about-personal-stuff /
Google memiliki keunggulan halaman dukungan yang dapat membantu Anda membuat file robots.txt jika Anda belum pernah membuatnya sebelumnya. Ini bekerja sangat baik, seperti yang saya jelaskan baru-baru ini di sebuah artikel tentang menyusun penawaran sindikasi Cara Melakukan Negosiasi Penawaran Sindikasi Dan Melindungi Peringkat Pencarian AndaSyndicating adalah hal yang populer akhir-akhir ini. Tetapi tiba-tiba Anda dapat menemukan bahwa mitra sindikasi terdaftar lebih tinggi daripada Anda dalam hasil pencarian untuk sebuah cerita yang Anda tulis semula! Lindungi peringkat pencarian Anda. Baca lebih banyak sehingga mereka tidak menyakiti Anda (meminta mitra sindikasi untuk melarang pengindeksan halaman mereka di mana Anda disindikasikan). Setelah mitra sindikasi saya setuju untuk melakukan ini, halaman yang digandakan konten dari blog saya sepenuhnya hilang dari daftar pencarian.
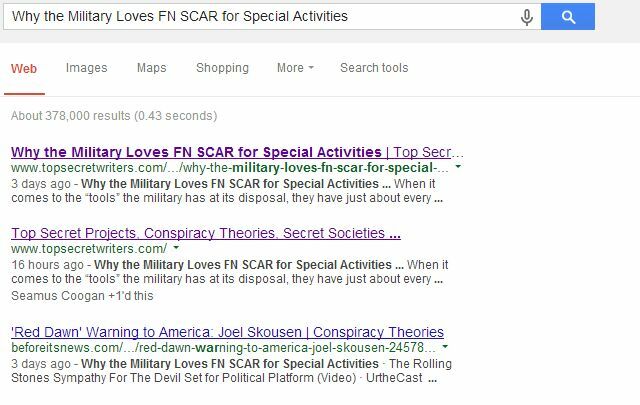
Hanya situs web utama yang muncul di tempat ketiga untuk halaman di mana mereka mendaftarkan judul kami, tetapi blog saya sekarang terdaftar di tempat pertama dan kedua; sesuatu yang hampir mustahil jika situs web otoritas yang lebih tinggi membiarkan halaman yang diduplikasi diindeks.
Apa yang banyak orang tidak sadari adalah bahwa ini juga mungkin dicapai dengan Internet Archive (the Wayback Machine) juga. Berikut adalah baris yang perlu Anda tambahkan ke file robots.txt Anda untuk mewujudkannya.
Agen-pengguna: ia_archiver. Disallow: / sample-kategori /
Dalam contoh ini, saya memberi tahu Internet Archive untuk menghapus apa pun di subdirektori kategori sampel di situs saya dari Mesin Wayback. Arsip Internet menjelaskan cara melakukan ini di halaman bantuan Pengecualian mereka. Di sinilah mereka menjelaskan bahwa “Arsip Internet tidak tertarik menawarkan akses ke situs web atau dokumen Internet lainnya yang penulisnya tidak ingin materi mereka ada di dalam koleksi.”
Lalat ini bertentangan dengan kepercayaan umum bahwa segala sesuatu yang diposkan ke Internet tersapu ke dalam arsip untuk selamanya. Tidak - webmaster yang memiliki konten dapat secara khusus menghapus konten dari arsip dengan menggunakan pendekatan robots.txt.
Hapus Halaman Individual Dengan Meta Tag
Jika Anda hanya memiliki beberapa halaman individual yang ingin Anda hapus dari hasil Google Penelusuran, Anda sebenarnya tidak perlu menggunakan pendekatan robots.txt sama sekali, Anda cukup menambahkan meta tag "robot" yang benar ke setiap halaman, dan memberi tahu robot tersebut untuk tidak mengindeks atau mengikuti tautan di keseluruhan halaman.
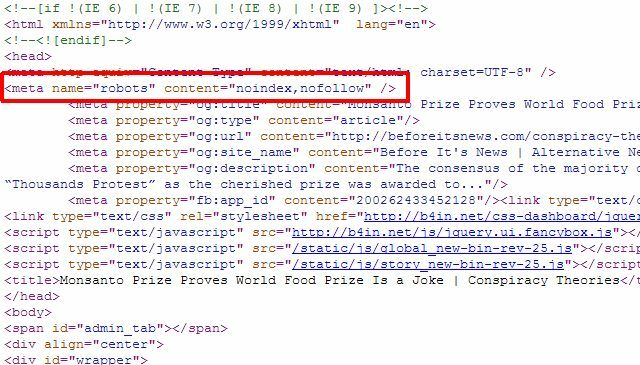
Anda dapat menggunakan meta "robot" di atas untuk menghentikan robot agar tidak mengindeks halaman, atau Anda dapat secara khusus memberi tahu robot Google tidak mengindeks sehingga halaman hanya dihapus dari hasil pencarian Google, dan robot pencarian lainnya masih bisa mengakses halaman kandungan.
Ini sepenuhnya terserah Anda bagaimana Anda ingin mengelola apa yang robot lakukan dengan halaman tersebut dan apakah halaman tersebut terdaftar atau tidak. Untuk beberapa halaman saja, ini mungkin pendekatan yang lebih baik. Untuk menghapus seluruh direktori konten, buka metode robots.txt.
Gagasan "Menghapus" Konten
Jenis ini mengubah seluruh gagasan "menghapus konten dari Internet" di kepalanya. Secara teknis, jika Anda menghapus semua tautan Anda sendiri ke suatu halaman di situs Anda, dan Anda menghapusnya dari Google Search dan Internet Archive menggunakan teknik robots.txt, halaman ini untuk semua maksud dan tujuan "dihapus" dari Internet. Namun hal yang paling keren adalah bahwa jika ada tautan ke halaman tersebut, tautan itu akan tetap berfungsi dan Anda tidak akan memicu 404 kesalahan bagi pengunjung tersebut.
Ini adalah pendekatan yang lebih "lembut" untuk menghapus konten dari Internet tanpa sepenuhnya mengacaukan popularitas tautan situs Anda yang ada di seluruh Internet. Pada akhirnya, bagaimana Anda mengelola konten yang dikumpulkan oleh mesin pencari dan Arsip Internet terserah Anda, tetapi selalu ingat bahwa terlepas dari apa yang orang katakan tentang umur hal-hal yang diposting online, itu benar-benar ada dalam Anda kontrol.
Ryan memiliki gelar BSc di bidang Teknik Listrik. Dia telah bekerja 13 tahun di bidang teknik otomasi, 5 tahun di bidang TI, dan sekarang adalah seorang Insinyur Aplikasi. Mantan Redaktur Pelaksana MakeUseOf, dia berbicara di konferensi nasional tentang Visualisasi Data dan telah ditampilkan di TV dan radio nasional.